
Pruned Cross Validation
2019-03-22 Pruned Cross Validation for hyperparameter optimization
The new technique’s motivation, design, and implementation
Introduction
There are several reasons why you would like to use cross-validation: it helps you to assess the quality of the model, optimize its hyperparameters and test various architectures. There are also a variable number of reasons why you wouldn’t like it - this variable is the number of folds. For each fold, the model has to be trained. With computationally intensive algorithms and big datasets, training each fold may be a cumbersome endeavor.
This is a challenge I recently faced in order to optimize hyperparameters of a stacked model. I used a Bayesian optimization package to do it (I described it in my Towards Data Science article) with 12 folds. The effect was a raging frustration.
Some of the trials (hyperparameters set and cross-validation) took extremely long to train, and to my despair, yielded much worse results than the ten times quicker ones. At some point I started to print each folds score, it’s hyperparameters, and execution time only to watch it progress and understand what should I change in the search space. As you can imagine I got frustrated by the fact that I was manually overseeing an automatic process! Something had gone wrong.
By looking at folds scores, I realized that within only the first 2–3 folds’ scores I was able to tell whether the total score would be decent or not. There were some very long trials which by fold 3 out of 12 I was sure would yield poor results. As you can imagine that made me think what would happen if I just stopped after the first folds, evaluated the results and went on if the trial was promising or prune it if it was not. But it’s not proper cross-validation, right?
Cross-validation recap
Cross-validation is a technique to assess a model’s quality. First, you should choose a metric, which would represent the quality of your model. Then you split your training dataset into n number of subsets, called folds (note you should use stratification if possible to ensure similar distributions in each set). Then you should train your model n times, at each time the training set is composed of n - 1 subset. The remaining one is treated as a validation set, left for metric evaluation. Then the scores are averaged across the folds and presented as the final metric.

The technique allows you to verify your model’s quality on the whole dataset available, and therefore present the best possible estimation of its performance on unseen data. Its main disadvantage is a necessity of training the same model n times. Performing hyperparameters optimization requires many folds and therefore the computation time is high.
The pruning idea
As you can imagine scores from the folds and the final score are dependent on each other. I’ve made a few simulations studies to evaluate the correlation between cumulative metrics value after each fold and the final score.
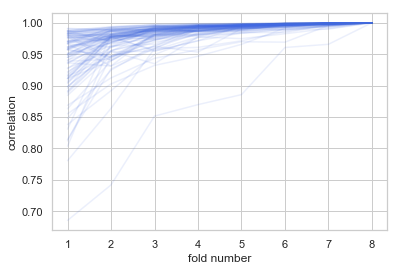
As you can see in this case the correlation with the final score rises very fast with subsequent folds reaching 0.98 on fold 3 out of 8. The idea of pruned cross-validation is based on the high correlations and our ability to partially assess the hyperparameters set without calculating all the folds.
The pruned cross-validation algorithm
The algorithm is based on a deterministic comparison between equivalent folds’ scores.
Parameters:
- n - number of folds (integer, >= 2)
- t - tolerance (float, >=0.0, default=0.1)
- k - fold number at which first pruning may happen (integer, <= n, default=2)
The algorithm:
- Define a model, a hyperparameters space and pruning parameters
- Choose an initial set of hyperparameters to evaluate
- Calculate full cross-validation, save scores for all folds and the final score
- Choose a hyperparameters set to evaluate
- Calculate fold’s score
- If the fold number is lower than k, got to the beginning of point 5.
- If the folds number is equal to n calculate the final score
- If the score is lower than the best score so far, set its hyperparameters and best scores as the best one
- Evaluate whether current trial’s mean score is below mean value of the best trial’s scores (the same number as the ongoing trial) multiplied by (1 + t)
- If yes, got to point 5.
- Else, prune the trial, estimate the final score and go to point 4. otherwise
The algorithm ensures that the best hyperparameters are validated on all the folds, but it does not guarantee to find the best hyperparameters out of evaluated ones. A model can strongly underperform on initial folds and outperform on the latter ones. Even with medium sized datasets and proper data shuffle it’s highly unlikely.
Speed benchmarking
The main advantage of the pruned cross-validation is a search speed increase. If the hyperparameters set yields poor results, the cross-validation is pruned and therefore time, and computation resources are saved.
Below you can find a comparison between standard grid search and pruned grid search:
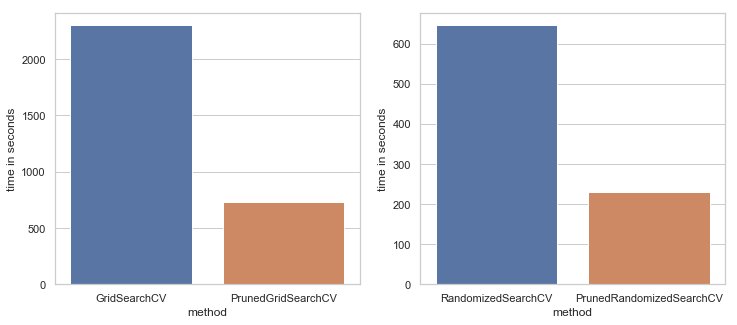
Grid Search with pruned cross-validation was over three times faster than the traditional full validation search. Pruned Randomized Search was almost three times faster than its unpruned version from scikit-learn. The code of the experiment may be found in this notebook.
Lower and upper speed bounds compared to full cross-validation
The current implementation of the algorithm is based on simple lists operations, so its computation cost may be considered non-existent. Because of that, the upper boundary of the time is equal to the time needed for full cross-validation. The lower limit is equivalent to full computing cross-validation in the first trial, and k / n folds in following ones, where k is the first folds do try pruning, and n is the number of folds for cross-validation. With the high number of trials, the value should converge to k / n.
Implementation
The method was implemented in pruned-cv Python package (you can find it here)). Two search algorithms were implemented: PrunedGridSearchCV and PrunedRandomizedSearchCV. They have similar API as scikit-learn implementations of GridSearchCV and RandomizedSearchCV. They don’t offer final model refit though. Please refer to docstrings for more details.
The package also provides PrunedCV class. It’s the working horse of the package and can be used with other search algorithms like Bayesian Hyperparameter Optimization. Below you can find a pseudocode example with Optuna package:
import optuna
from prunedcv import PrunedCV
prun = PrunedCV(12, 0.1)
def objective(trial):
params = choose parameters for the trial
model.set_params(**params)
return prun.cross_val_score(model, x, y)
study = optuna.create_study()
study.optimize(objective, timeout=120)
model.set_params(**study.best_params)
model.fit(x, y)
You can find a benchmarking notebook with Optuna here and Hyperopt here. In the examples provided pruning limited trial’s duration 2.8 and 5.7 times respectively leading to better final scores in both cases.
Research fields
There are several fields of research connected with the technique worth exploring:
-
How to find the best fold to start pruning?
-
How to find the best tolerance value prior to the study?
-
How does the number of folds corresponds with cumulative scores correlations with the final score?
-
How to predict the final score better?
-
Is it possible to prune the trials in a probabilistic way?
Summary
The pruned cross-validation technique allows you to save time and resources needed for hyperparameter optimization (it’s possible to calculate higher and lower time-saving bonds in comparison to full cross-validation). It ensures the same level of overfitting prevention as standard cross-validation but does not guarantee the selection of the best parameters out of the verified ones.
The pruned-cv package is in version 0.0.1. It’s at a very early stage of development and implements the technique only for L1 and L2 regression and classification with accuracy score.
Please let me know what do you think about the technique and the package! I would appreciate feedback from you. If you wish to help me in package development or are interested in research regarding the method, please don’t hesitate to contact me!